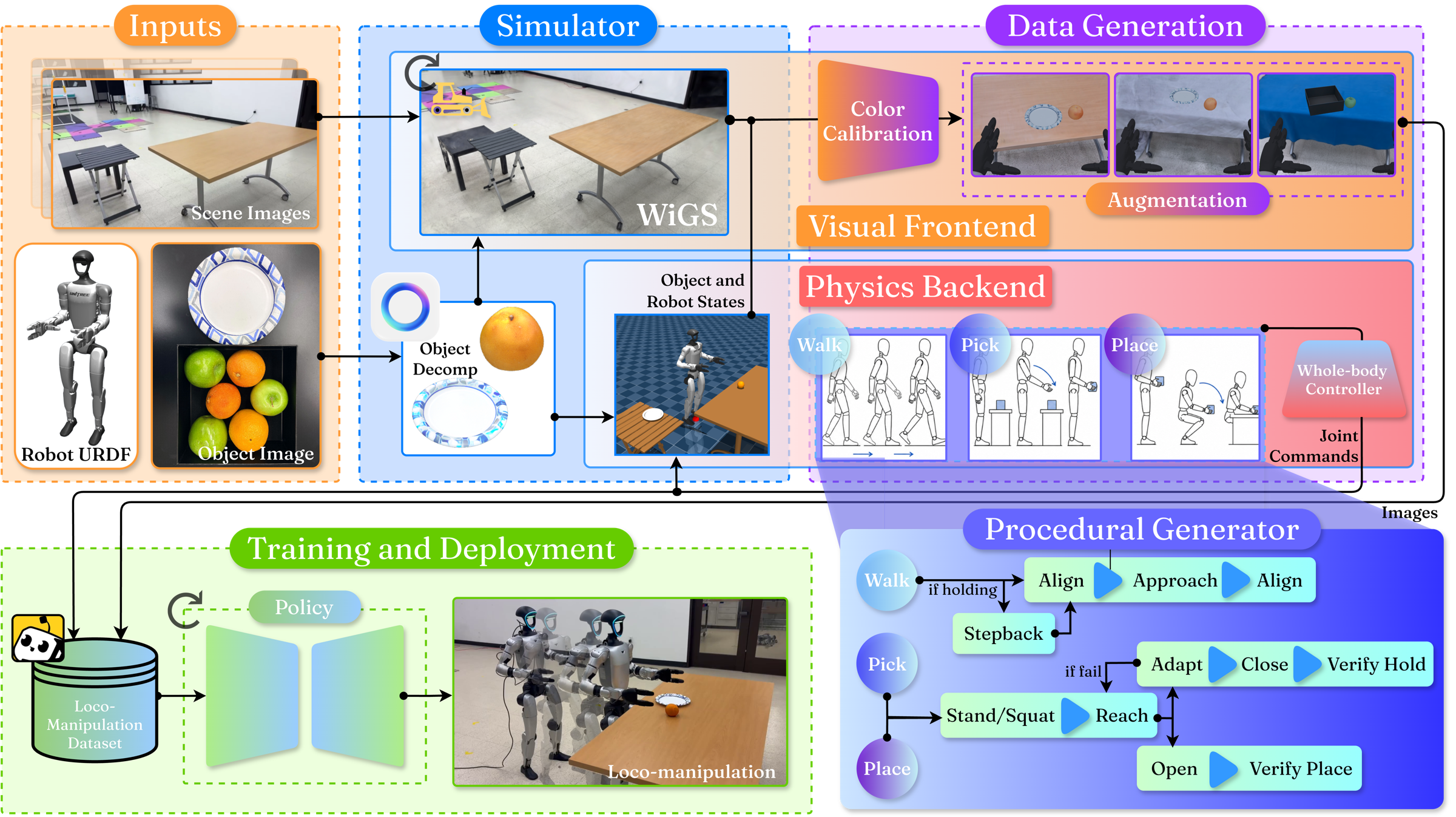
Method
A phone scan in. A humanoid skill out. Everything in between is synthesized.
1
Capture
Handheld scene video + one photo per object
2
Reconstruct
3DGS background + SAM3D object meshes
3
Simulate & Generate
Procedural demos in MuJoCo physics ⊕ calibrated 3DGS render
4
Deploy
Fine-tune a VLA → zero-shot on Unitree G1
hover a step — or a part of the pipeline — to highlight it
Two-stage color calibration
A deterministic two-stage calibration aligns the render to the robot's deployment camera — the first stage calibrates the object mesh, and the second is applied to both the mesh and the 3DGS background.



raw 3DGS + mesh
mesh calibrated
mesh + 3DGS calibrated

real camera



raw 3DGS + mesh
mesh calibrated
mesh + 3DGS calibrated

real camera
One episode, many appearances
1 recorded episode
motion only — independent of appearance
re-render: ~0.1 GPU-hr per condition
re-render with
new 3DGS background
new objects
new prompts
wood
blue
white
wood
blue
white
wood
blue
white